背景 随着我司业务规模逐年增长,业务需求迭代提速,同一个服务可能存在多个同时开发和测试的功能。在只有一套测试环境的情况下,容易发生抢占分支互相冲突影响的问题,降低开发测试效率。
另外,在时下的微服务架构中,一个功能可能需要依赖多个服务。在测试其中其中一个服务的改动时,如果依赖的服务发生了改动或者故障,也会影响这个功能的测试。
最后,当服务在测试中发现问题,需要开发修改时,开发需要经过修改代码 -> 重新提交 code review -> 提交到 master -> 重新发布到测试环境的整个流程,步骤繁琐,耗费时间的同时,也会让实现一个 feature 的 commit 变得分散。
这三个问题大大影响了项目并行开发的效率。因此,我们希望能够打通开发测试环境,基于 Service Mesh 服务网格 和 Kubernetes 容器编排 实现即插即用的上下游调用链路 ,也就是**泳道 (SwimLane)**。
什么是泳道 所谓 泳道 ,可以理解为多个并行隔离的调用链,调用互不干扰,类似泳池中的泳道。
发往特定泳道的请求会在特定泳道中部署的服务中流通,仅当泳道中不具备需要请求的服务,会发送到主干道,见下图:
不同的泳道之间请求不会互相访问,以此实现不同特性开发测试的隔离,进而:
不会存在同一服务抢占测试环境分支的问题
可以通过发布特定版本依赖服务到泳道中确保依赖服务不会变更 / 确保路由到具备特定特性的依赖服务
本地开发 / 修改完后无需 code review 即可发布到泳道中进行测试,待测试初步完成再一次提交完整的 code review
上述的几个痛点迎刃而解。
泳道需要具备的特性 要实现上述的功能,泳道需要具备哪些特性呢?
首先,泳道需要全链路泳道内转发 (除非泳道中没有服务可转发主干道)。对于流经服务 a -> b -> c 的请求链路,如果泳道中只有服务 a 和 c,即便请求在路由到服务 b 时经过主干道,在泳道内部署了服务 c 的情况下,同一链路的请求从主干道服务 b 流出时还应该转发回泳道中的服务 c 而不是主干道中的服务 c。
这个功能首先需要基于 HTTP header 的流量转发 ,可以识别发往泳道的请求并发往泳道服务。在此基础上,需要关联全链路请求 ,服务 b 发出的请求和其接收到的 服务 a 过来的请求可以关联上,需要服务内部的链路追踪。
其次,还需要进行泳道自身的生命周期管理 ,在泳道存活时,能够发布、更新泳道中的应用;在泳道销毁或过期后,能够自动销毁其中的应用释放资源。
方案探索 我司彼时已经完成了服务整体架构到基于 Istio 的 Service Mesh 服务网格 的迁移。
Service Mesh 本身具备强大的定制路由能力,通过 Istio 的 VirtualService 和 DestinationRule 就可以实现基于 HTTP Header 的转发。
然而,单层的转发很简单,怎么实现链路全程转发呢?要实现全程转发要关联整个链路的请求,相当于要知道服务 b 发出的哪些请求是由泳道中的服务 a 触发的。从理论上来说,不做代码层的修改是无法做到的。
幸运的是,不过这件事情并不需要我们做,关联整条链路是链路追踪系统的工作。链路追踪系统堆砌了大量的工作在修饰各种框架、客户端上,我们只需要利用它的结果即可。
在请求流入时,如果请求具备泳道 id,sidecar 可以存储其对应的 trace id 到泳道 id 的映射;在请求流出时,检查存储中是否具备当前 trace id 的映射,如果有,则为请求添加泳道 id,这样即可实现链路的全程转发:
路由转发的问题有解法后,泳道自身的定义、应用部署与更新、生命周期管理以及对 Service Mesh 路由规则的自动修改,可以使用 Kubernetes 偏好的方式: CRD 及对应的Controller 来解决。
泳道的概念将使用单独的 SwimLane CRD 表示,一条泳道对应一个 CRD 对象实例。Deployment 。在一个泳道的生命周期中,可能会加入新的 Deployment ,去除之前添加的 Deployment ,以及更新其中已有的 Deployment 的参数,例如image ,replica 数量等。而 SwimLane Controller 负责监听泳道对象的变化并负责朝着理想的终态推进。
落地实践 Traffic Labelling Envoy Filter Envoy 支持通过 WASM 在不重新打包的情况下通过在sidecar 中插入自定义逻辑。proxy-wasm-abi ,用户可以通过多种源语言 (目前官方支持 C++, Rust, Go) 引入 proxy-wasm sdk 以回调的方式对请求进行各种操作。
此处使用 Rust 实现了 traffic_label_inbound 以及 traffic_label_outbound 两个插件分别作用于 sidecar 的请求流入端和流出端,核心逻辑如下:
Inbound 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 impl wasm ::traits::HttpContext for TrafficLabelInbound { fn on_http_request_headers (&mut self , _num_headers: usize , _end_of_stream: bool ) -> Action { self .remove_expired_label_mappings (); let trace_id = self .get_http_request_header (TRACE_ID_HEADER_NAME); if trace_id.is_none () { debug!("No trace id header presents in request." ); return Action::Continue; } let trace_id = trace_id.unwrap (); let mut label_headers = Headers::new (); REQUEST_LABEL_HEADERS.with (|headers| { if let Some (some_headers) = headers.borrow ().deref () { for header in some_headers.iter () { let header_value = self .get_http_request_header (header); match header_value { None => { debug!("No label header {} presents in request." , header); continue ; } Some (header_value) => { label_headers.push (Header::new (header.clone (), header_value)); } } } } }); if label_headers.is_empty () { return Action::Continue; } let headers_bytes = bincode::serialize (&label_headers).unwrap (); SHARED_CACHE.with (|cache| { match cache.borrow_mut ().set_shared_cache (&trace_id, &headers_bytes[..], None ) { Ok (_) => debug!( "Stored label headers: {:?} for trace: {}" , &label_headers, &trace_id ), Err (e) => error!( "Error occurred storing label headers: {:?} for trace: {}, status: {:?}" , &label_headers, &trace_id, e ), } }); SLIDING_BUCKETS.with (|b| { b.borrow_mut ().as_mut ().unwrap ().put (trace_id); debug!("Sliding buckets: {:?}" , b.borrow ()); }); wasm::types::Action::Continue } }
Inbound 部分负责存储 trace id 到随携 header 的映射。
共享存储 值得一提的是,wasm 代码是由 sidecar 中各个线程的 wasm vm 执行,多个 worker thread 存在多个 vm,并且分为 inbound 和 outbound 两个 filter,因此这部分存储需要跨 VM 通信,见 cross-vm-communications 。此处使用了 shared-data 进行存储,可以理解为一个共同可见的本地内存 kv 存储库。(此处提供的链接是 go sdk 的,因为这里的文档比较详细一些)。
令人难受的是,proxy-wasm 对 shared data 的实现有所缺陷,没有提供删除接口,即便对 key 的值设置为空,key 仍然要占据空间。对于一些场景来说也许可以接收,但是对于此处以 trace id 为 key 的场景来说却是致命的,因为 trace id 量大且不重复,以它作为 key 将会导致内存泄露无法回收,应用将会慢性死亡。
proxy-wasm 的更新非常缓慢,中间也发生了一些争议,此处只能自力更生,封装了 shared_cache 库解决此问题,核心逻辑很简单,在 shared data 中开辟一定数量的桶,以桶 id 为 key,将真正要存储的 kv 经过 hash 并序列化,存储到桶中。在性能上可能会稍逊,但是毕竟场景是测试环境,可以接受,以一小部分性能损耗以及微小的空间占用避免内存无限泄露的问题。
部分核心逻辑如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 pub struct SharedCache { bucket_count: usize , } impl SharedCache { pub fn new (bucket_count: usize ) -> SharedCache { SharedCache { bucket_count } } pub fn get_shared_cache (&self , key: &str ) -> Result <(Option <Bytes>, Option <u32 >), Status> { let shared_data_res = hostcalls::get_shared_data (&self .slot (key)); match shared_data_res { Ok ((bytes, cas)) => { match bytes { Some (bytes) => { let bucket : Bucket = bincode::deserialize (&bytes).unwrap (); Ok ((bucket.get (key), cas)) } None => Ok ((None , cas)), } } Err (_) => shared_data_res, } } pub fn set_shared_cache ( &mut self , key: &str , value: &[u8 ], cas: Option <u32 >, ) -> Result <(), Status> { let key_slot = self .slot (key); let res = match cas { Some (outer_cas) => { let shared_data_res = hostcalls::get_shared_data (&key_slot); match shared_data_res { Ok ((bytes, _)) => { match bytes { Some (bytes) => { let mut bucket : Bucket = bincode::deserialize (&bytes).unwrap (); bucket.insert (key.to_string (), value.to_vec ()); hostcalls::set_shared_data ( &key_slot, Some (&bucket.to_bytes ()), Some (outer_cas), ) } None => { let mut bucket = Bucket::new (); bucket.insert (key.to_string (), value.to_vec ()); hostcalls::set_shared_data ( &key_slot, Some (&bucket.to_bytes ()), Some (outer_cas), ) } } } Err (status) => Err (status), } } None => { let mut res : Result <(), Status> = Ok (()); loop { let shared_data_res = hostcalls::get_shared_data (&key_slot); match shared_data_res { Ok ((bytes, inner_cas)) => { match bytes { Some (bytes) => { let mut bucket : Bucket = bincode::deserialize (&bytes).unwrap (); bucket.insert (key.to_string (), value.to_vec ()); match hostcalls::set_shared_data ( &key_slot, Some (&bucket.to_bytes ()), inner_cas, ) { Ok (_) => break , Err (Status::CasMismatch) => continue , Err (status) => { res = Err (status); break ; } } } None => { let mut bucket = Bucket::new (); bucket.insert (key.to_string (), value.to_vec ()); match hostcalls::set_shared_data ( &key_slot, Some (&bucket.to_bytes ()), inner_cas, ) { Ok (_) => break , Err (Status::CasMismatch) => continue , Err (status) => { res = Err (status); break ; } } } } } Err (status) => res = Err (status), }; } res } }; debug!("Set key: {} at shared cache bucket: {}" , key, key_slot); res } ... }
过期删除 由于是内存存储,且因为 trace id 的时效性,肯定不能无限存,所以需要一个过期机制来进行删除,这里实现了一个简单的滑动桶,每秒存储的 trace id 会落入一个桶中,维持一个 30s 的队列,请求进入时判断是否要进行过期清除。
outbound outbound 部分则是执行相反的工作,从 shared_cache 中获取根据 trace id 中获取 header 并打到流出请求中。
不过此处有个特例,就是对于单纯的请求发出方,例如任务调度器,如果它部署在泳道中,它主动发出的请求也应该带上泳道 header。此处可以通过配置让 filter 从 pod 环境变量中获取泳道 id,在这类应用发出请求时统一打上泳道标签。
部分代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 impl wasm ::traits::HttpContext for TrafficLabelOutbound { fn on_http_request_headers (&mut self , _num_headers: usize , _end_of_stream: bool ) -> Action { LABEL_ALL_OUTBOUND_TRAFFIC.with (|label_all_outbound_traffic| { if *label_all_outbound_traffic.borrow () { LABEL_HEADERS.with (|headers| { let borrowed_headers = headers.borrow (); match borrowed_headers.deref () { None => { debug!("No label headers specified for outbound traffic." ); return Action::Continue; } Some (headers) => { debug!("Instpected label headers: {:?}" , headers); for header in headers.iter () { VAR_RESOLVER.with (|resolver| { match resolver.borrow_mut ().resolve (&header.value) { Some (header_value) => { self .set_http_request_header ( &header.name, Some (header_value), ); debug!("Added header: {} to request." , &header.name); } None => { debug!("No value resolved for header: {:?}." , &header); } } }); } return Action::Continue; } } }); } }); let trace_id = self .get_http_request_header (TRACE_ID_HEADER_NAME); if trace_id.is_none () { debug!("No trace id header presents in request." ); return Action::Continue; } let trace_id = trace_id.unwrap (); debug!( "Inspecting shared data for label headers with trace id: {}" , trace_id ); SHARED_CACHE.with (|cache| match cache.borrow ().get_shared_cache (&trace_id) { Ok (opt_bytes) => match opt_bytes { (Some (bytes), _) => { let headers : Result <Headers, Box <bincode::ErrorKind>> = bincode::deserialize (&bytes); match headers { Ok (headers) => { debug!( "Inspected label headers {:?} stored for trace id: {}" , headers, trace_id ); for header in headers.iter () { self .set_http_request_header (&header.name, Some (&header.value)); debug!( "Added header: {:?} to request with trace id: {}" , header, trace_id ); } } Err (e) => { error!("Error occurred during deserialization: {}" , e); } } } (None , _) => { debug!("No label headers found with trace id: {}" , trace_id); } }, Err (status) => { error!("Unexpected status: {:?}" , status) } }); return Action::Continue; } }
为了节省内存,提高性能,这两个 filter 可以打包到一起,通过 Istio 的 Envoy Filter 配置到各个应用的 sidecar 中,即时生效:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 apiVersion: networking.istio.io/v1alpha3 kind: EnvoyFilter metadata: name: traffic-label-wasm-extension namespace: istio-system spec: configPatches: - applyTo: EXTENSION_CONFIG patch: operation: ADD value: name: traffic-label-inbound typed_config: "@type" : type.googleapis.com/envoy.extensions.filters.http.wasm.v3.Wasm config: configuration: "@type" : type.googleapis.com/google.protobuf.StringValue value: '{"plugin_type": "traffic_label_inbound", "plugin_conf": "{\"request_label_headers\":[\"fintopia-swim-lane-id\"],\"response_label_headers\":[{\"name\":\"fintopia-swim-lane-id\",\"value\":\"${VERSION:unknown}\"}],\"bucket_time_range_in_secs\":1,\"data_expire_time_in_secs\":30}"}' fail_open: true name: traffic_label_inbound root_id: traffic_label_inbound vm_config: code: local: filename: /var/local/wasm/dev/traffic_label_all_in_one.wasm environment_variables: host_env_keys: - VERSION - LABEL_ALL_OUTBOUND_TRAFFIC runtime: envoy.wasm.runtime.v8 vm_id: traffic_label - applyTo: EXTENSION_CONFIG patch: operation: ADD value: name: traffic-label-outbound typed_config: "@type" : type.googleapis.com/envoy.extensions.filters.http.wasm.v3.Wasm config: configuration: "@type" : type.googleapis.com/google.protobuf.StringValue value: '{"plugin_type": "traffic_label_outbound", "plugin_conf": "{\"label_all_outbound_traffic\":\"${LABEL_ALL_OUTBOUND_TRAFFIC:false}\",\"label_headers\":[{\"name\":\"fintopia-swim-lane-id\",\"value\":\"${VERSION:unknown}\"}]}"}' fail_open: true name: traffic_label_outbound root_id: traffic_label_outbound vm_config: code: local: filename: /var/local/wasm/dev/traffic_label_all_in_one.wasm environment_variables: host_env_keys: - VERSION - LABEL_ALL_OUTBOUND_TRAFFIC runtime: envoy.wasm.runtime.v8 vm_id: traffic_label
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 apiVersion: networking.istio.io/v1alpha3 kind: EnvoyFilter metadata: name: traffic-label-envoy-filter namespace: istio-system spec: configPatches: - applyTo: HTTP_FILTER match: listener: filterChain: filter: name: envoy.filters.network.http_connection_manager subFilter: name: envoy.filters.http.router context: SIDECAR_INBOUND patch: operation: INSERT_BEFORE value: config_discovery: config_source: ads: {} type_urls: - type.googleapis.com/envoy.extensions.filters.http.wasm.v3.Wasm name: traffic-label-inbound - applyTo: HTTP_FILTER match: listener: filterChain: filter: name: envoy.filters.network.http_connection_manager subFilter: name: envoy.filters.http.router context: SIDECAR_OUTBOUND patch: operation: INSERT_BEFORE value: config_discovery: config_source: ads: {} type_urls: - type.googleapis.com/envoy.extensions.filters.http.wasm.v3.Wasm name: traffic-label-outbound
配置上之后,即可实现全链路 swimlane header 透传。
SwimLane CRD & CRD Controller CRD CRD 为用户自定义的 K8S 中的对象,K8S 会提供简单的增删改查管理,搭配 CRD 以及对应的 Controller (读取 CRD 状态,推动 K8S 集群中的一切对象朝着此终态前进) 是一种普遍的扩展 K8S 的方式。
自然而然地,我们将泳道定义为 一个 SwimLane 类型的 CRD ,并实现对应的 Controller 来管理要实现泳道功能的 Istio VirtualService 和 DestinationRule (实现路由功能) 和 K8S deployment (实现部署功能)。
关于CRD主要包括这几部分:
泳道信息,即泳道名称、命名空间及泳道租期
服务部署列表,即对应泳道包含多个部署信息(镜像、名称、命名空间等),以及增强功能开关 (后续提到)
泳道内中间件的部署,实现支持消息队列等中间件的泳道部署与路由 (后续提到)
下面是一个样例 CRD:
基于以上的CRD 定义,我们在部署泳道及其服务就比较方便了,只需要在CICD过程中,选择设置名称、命名空间和镜像,就可以拉起一个新版的POD.
Controller 接下来 Controller 需要解决以下几个问题
泳道服务基于基础版本deployment修改,并进行部署
基于ISTIO,请求按照header路由到指定泳道,并支持泳道内服务的多跳
泳道租期过期与续期,防止资源的浪费
对于增强特性,需要对泳道镜像设置特殊环境变量,并且自动开通远程端口
部署泳道内中间件以及设置智能DNS,实现访问泳道内中间件
在逻辑上,Controller 分为以下几个模块:
Deployment Manager
这个模块主要功能根据泳道信息及属性和基础版本内容,设置泳道内 Kubernetes Deployment 。
对泳道创建的 Kubernetes Deployment ,我们需要重新设置其以下属性:
覆盖原版name,新版name为{name:{deployments.name}-{swimlane.name}}
将之前Selector和Template的Label[“version”]的stable为泳道name
为了实现资源的分类,需要对泳道的服务增加节点亲和度
将replicas统一设置为1,因为泳道内的服务仅为测试使用
设置主容器的镜像以及VERISON的环境变量,方便容器内服务判断环境
根据我们的增强功能开关, 设置JAVA_OPTS 环境变量,用于启动java进程,并开启对应的端口。然后在镜像的java启动命令中增加{JAVA_OPTS}环境变量,这样我们就可以开启agent。
Informer Service
Informer VirtualService :由于一个K8S_FQDN_HOST 可能被多个 VirtualService 指向,因此我们如果需要修改某个K8S_FQDN_HOST 的流量,我们可能同时修改多个对应VirtualService对象,因为我们必须建立K8S_FQDN_HOST -> VirtualService,才可以完全修改对应服务的流量。
Informer K8sService :针对于一些高级特性,比如远程debug等,需要开启NodePort,从而让我们的开发人员连接到对应的进程。所以依赖同步K8S Service解析NodePort -> Service 映射关系, 实现NodePort的自动分配和回收。
SubResource Manager
SubResource Manager 负责管理 Istio 中的 VirtualService 和 DestinationRule 路由规则。
在发布应用到泳道时,需要在 DestinationRule 中添加对应版本的服务子集:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 apiVersion: networking.istio.io/v1beta1 kind: DestinationRule metadata: name: foo-api-destination-rule namespace: infra spec: host: foo-api.infra.svc.cluster.local subsets: - labels: version: stable name: stable - labels: version: foo-api-test name: foo-api-test
随后修改 VirtualService ,增加依赖 泳道 HTTP Header 的路由规则:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 apiVersion: networking.istio.io/v1beta1 kind: VirtualService metadata: name: foo-api namespace: infra spec: hosts: - foo-api.infra.svc.cluster.local http: - match: - headers: fintopia-swim-lane-id: exact: foo-api-test name: foo-api-test-swimlane-vs route: - destination: host: foo-api.infra.svc.cluster.local subset: foo-api-test - name: stable route: - destination: host: foo-api.infra.svc.cluster.local subset: stable
以上为 Controller 的主要逻辑,余下的一些细节就不过多赘述啦。
特性演进 泳道上线以来,结合大家的使用体验,我们陆续为泳道增加了几个对开发测试流程有帮助的特性,分别是:
Java 应用远程 Debug中间件泳道部署
Java 应用远程热部署
以上三个特性能够提高开发测试的体验和效率,下面将分别大致介绍一下。
Java 应用远程 Debug 在泳道的使用场景,开发在本地开发 -> 发布泳道的流程中,如果碰到一些问题,但是本地又不好造数据/环境复现的情况下,对应用进行远程 Debug 能够很好地解决问题,提升开发效率。
JDWP: The Java Debug Protocol JDWP 是 JVM 和 Debugger 进行通信的协议,通过 JDWP 可以实现 Debugger 和 JVM 进程在以下环境工作:
JDWP 的底层通过 TCP 协议进行传输。
使用 Debug 模式编译以及启动 Java 应用 为了在 Debug 的时候可以直观地看到代码的行数、变量名等,需要在编译的时候保留 Debug 信息,加上 -g 参数。不过我们的项目通常使用 Maven 进行打包,默认保留 Debug 信息,因此可以忽略。
启动应用时,需要加上 Debug 相关的参数以及指定端口,如
1 java -agentlib:jdwp=transport=dt_socket,server=y,suspend=n,address=8000 OurApplication
启动后,即可用 Debugger 连接应用相关端口。以 Intellij Idea 自带的 Debug 功能为例:
泳道实现 在 Swimlane CRD 中添加 debug 参数:
如果用户在向泳道部署应用时选择启用 Java 远程 debug,则在生成的 Kubernetes Deployment 处添加上述的 Debug 启动参数,为其分配端口,同时在 Gateway 层分配端口并配置端口转发,开发只需要在 IDE 中配置对应的 host 和 port 即可。
中间件部署 当需要在泳道中测试一些会对中间件数据造成变更的操作,例如 Kafka 消息格式变更、灌输/删除 MySQL 数据时,如果能够像部署应用一样,在泳道中部署对应的中间件,仅在这个泳道中的应用可以访问,就会非常方便。
因此,我们对泳道功能进行了扩展,能够支持中间件入泳道。
由于一般中间件的地址没有注册到 Istio 服务发现系统中,因此,要进行路由,需要编写对应的 WorkloadEntry 以及 ServiceEntry 将其注册到 Istio 中,并赋予一个逻辑域名。以一个 Kafka 集群为例:
WorkloadEntry:
1 2 3 4 5 6 7 8 9 10 11 apiVersion: networking.istio.io/v1beta1 kind: WorkloadEntry metadata: name: business-kafka namespace: swimlane spec: address: 172.11 .11 .11 labels: app: kafka cluster: business version: stable
ServiceEntry:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 apiVersion: networking.istio.io/v1beta1 kind: ServiceEntry metadata: name: business-kafka-cluster namespace: swimlane spec: hosts: - business-kafka.fintopia.svc ports: - name: kafka number: 9092 protocol: TCP resolution: STATIC workloadSelector: labels: app: kafka cluster: business
随后开启 Istio DNS Proxy 让应用能够解析逻辑域名。由于中间件大多数使用 TCP 协议,需要一并开启 Address Auto Allocation 。
最后,在泳道 CRD 中添加中间件定义,并添加相关路由逻辑 (和应用的路由类似) 即可。
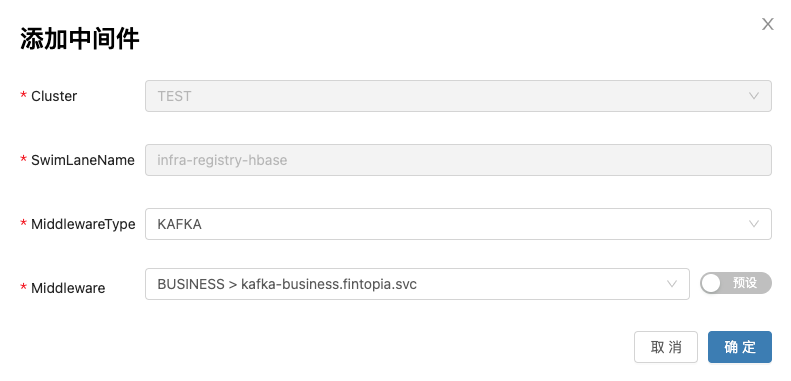
用户在泳道中可以点击添加中间件,添加需要的中间件类型。
远程热部署 对于大型应用 (编译时间足够吃顿饭的那种),改一行代码重新发泳道会花费许多不必要的时间。
通过在代码中继承远程热部署插件,可以在本地实时推送代码变更到泳道中的应用,秒级实现逻辑更新,再也不用经历长时间的构建发布启动流程,大大提高了泳道的使用体验。
实现方式类似 Java 远程 Debug,具体依赖热部署的实现方式而定,此处不再赘述。
总结 泳道是我司升级到 Istio 服务网格后一个很好的落地场景。
通过 Istio 服务网格带来的灵活路由能力以及 Sidecar 层的自由扩展能力,Infra Team 自主设计并实现了从 Traffic Label WASM Envoy Filter 到 SwimLane CRD & Controller,实现了泳道的功能并推广使用,随后陆续增加了 Java 远程 Debug、远程热部署、中间件泳道内部署的特性增强,提高了开发测试的流程效率,减少了多特性并行开发情况下的冲突问题。
在此基础上,我们对 Istio 的理解和应用包括扩展方面得到了部分实践的经验,分享出来,希望能对大家有一定的帮助。后续我们会开发落地更多对服务治理有帮助作用的功能,敬请期待。









