浅谈Compose中那些令人印象深刻的设计细节
引言
去年8月份Google正式发布compose1.0的稳定版本,为安卓平台带来了一套全新的声明式UI工具包。在此之后,经过一年的发展,compose借助KMM的跨平台特性,已经演进为一款跨平台的UI框架。
在过去的这段时间里,我机缘巧合通过一些小项目在桌面端对他进行了一番了解和体验。在使用的过程中,时不时的会被compose中的那些设计和实现所惊艳到。
当然,今天这篇不会涉及到太多的实现原理,但会跟大家聊一聊那些让我印象深刻的设计细节,希望可以激起大家对compose的兴趣。
Compose初体验
在开始之前,我想通过一个hello world例子带大家简单了解下如何使用compose,这里面会涉及到阅读这篇文章所需的背景知识。
声明下,本篇所贴出的代码虽然是在桌面平台运行,但与安卓上的使用方式并无太大区别,可以忽视因平台差异带来的一点点细节上的不同。
下面我直接在main方法中通过Compose提供的API来创建一个桌面平台上的窗口。
1 | fun main() = singleWindowApplication { |
在默认参数的情况下,singleWindowApplication方法会创建一个800dp*600dp的窗口,窗口内要展示的内容,可以直接在lambda内编写
比如展示一行48sp的文字
1 | fun main() = singleWindowApplication { |
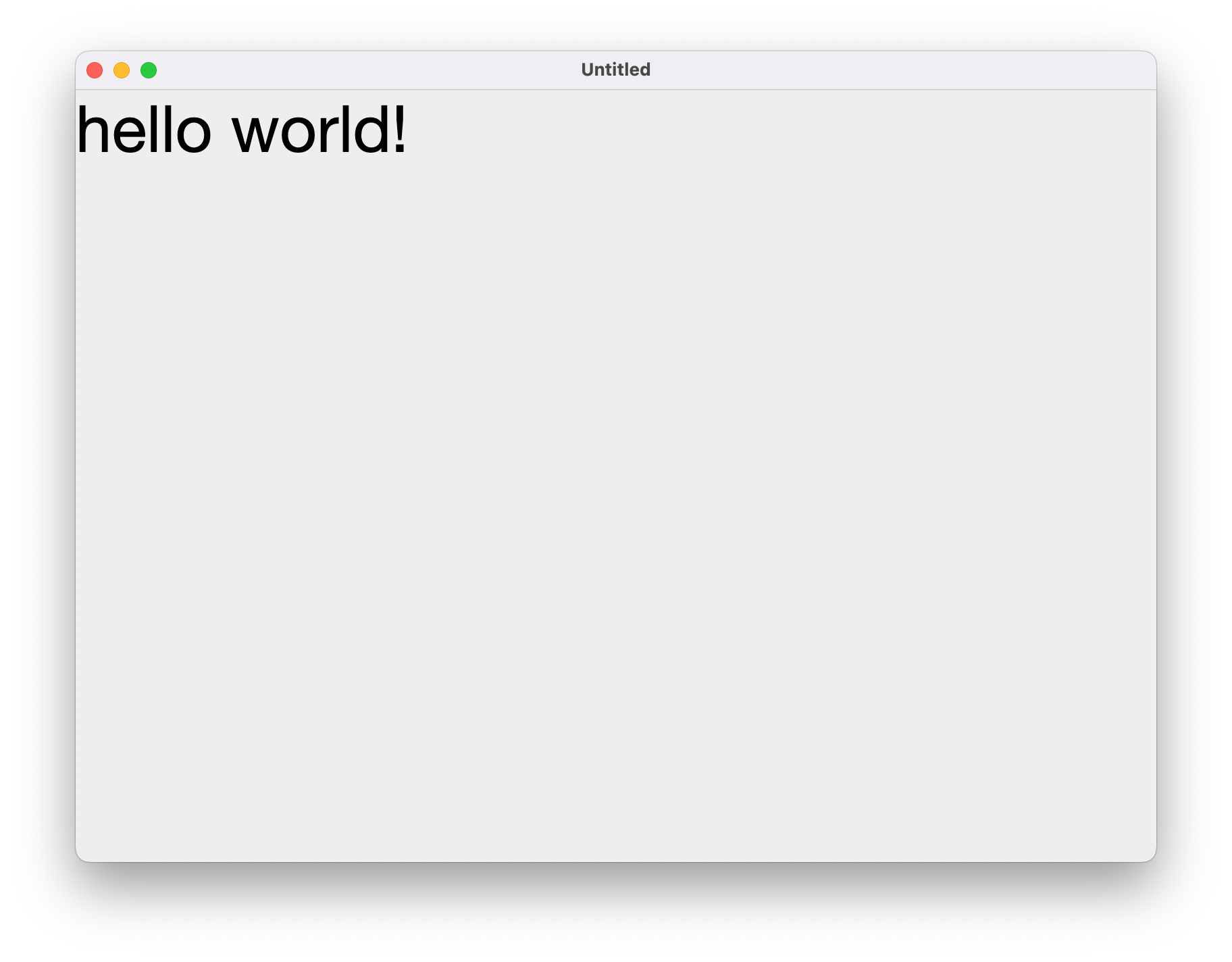
我们使用Text来展示这行文字。虽然调用的api首字母是大写,但其实他只是一个方法调用,我们为他传入了内容和字号两个参数,当代码运行起来以后,一个带有文本的窗口就显示出来了。
在Compose中,我们不直接通过创建View对象及设置其属性的方式来操作视图,而是通过一个个特殊方法的调用来声明页面细节,不同的方法调用相互组合嵌套,就可以用来描述当前页面的UI。
这样的特殊方法,被称作Composable(官翻为可组合项),声明一个Composable方法,需要为其标记@Composable注解。
比如刚刚用到的Text方法,其声明为
1 |
|
有了这个特殊的注解,编译器就可以很方便的定位到这样的方法并进行魔改,以便于在方法内部帮我们插入一些配合框架工作的代码。同理,标记了此注解的lambda也享受同等待遇。
虽然插入代码的工作在编译期进行,但你可能会因此意识到,这与Anko那种纯粹的用于创建View对象的工厂方法或dsl完全不是一类东西。
如果你后面看到很多颠覆认知的玩意儿,不要慌张,是编译器在搞鬼。
现在我们增加一些复杂度,给窗口内的文字包裹一层”FrameLayout”来使其在窗口内居中
1 | fun main() = singleWindowApplication { |
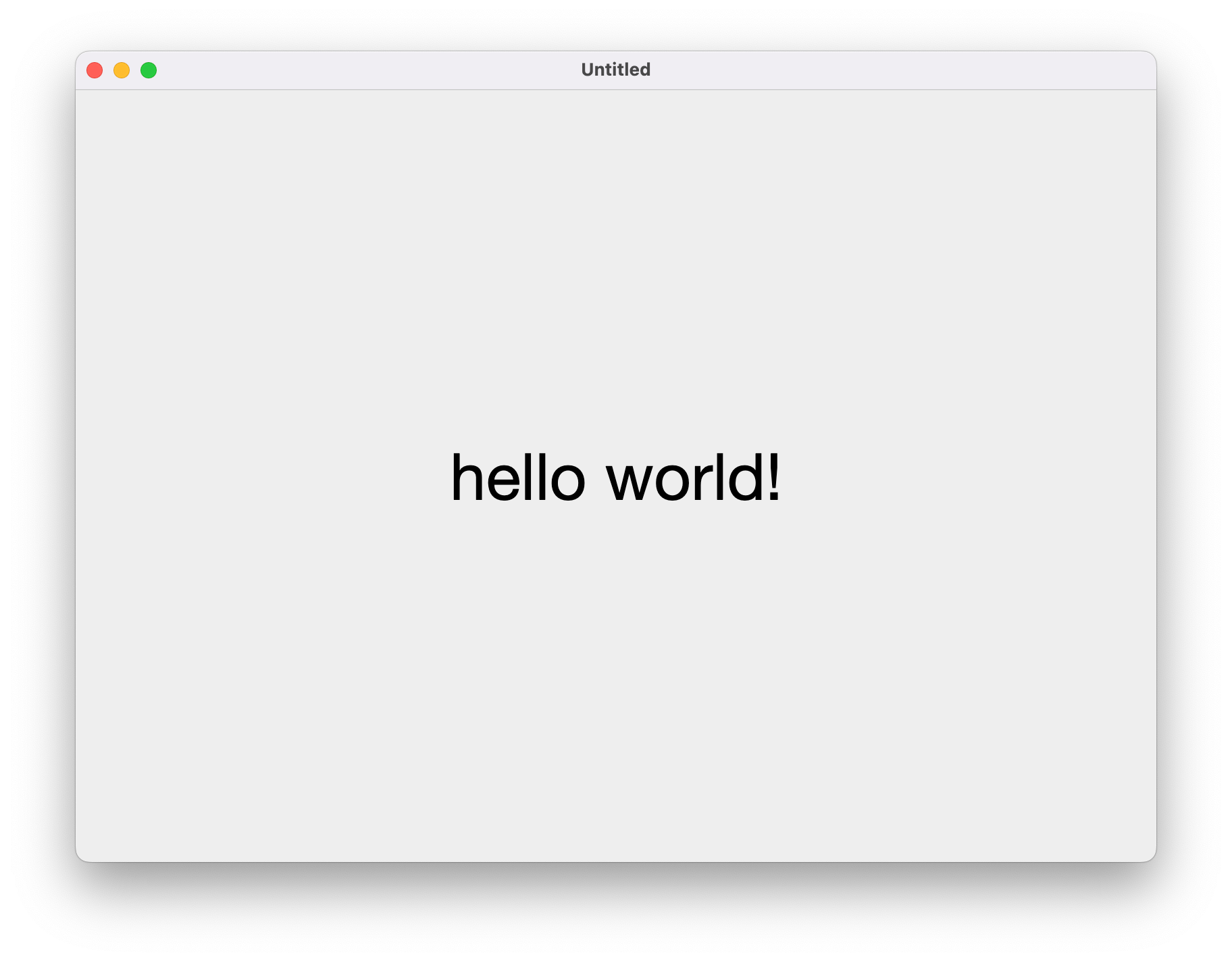
这次我们添加了一个Box,可以看做是安卓中的FrameLayout,Box的lambda内就是这个布局中具体要展示的内容,至于另外两个参数的意义,大家应该也可以猜到,就是设置撑满父布局以及居中展示子视图。
这种嵌套的写法在安卓的xml中非常常见。但讲到这里,他只能算是一个dsl版的xml,还不具备动态性。
接下来我们实现一个新功能,监听文字的点击事件并把点击次数展示在按钮上。代码和效果如下
1 | fun main() = singleWindowApplication { |

实现这个功能其实并没有对代码做过多的改动,通过Modifier.clickable {}设置了一个点击监听,然后新增了一个MutableState类型的对象count,点击回调中给count中的值加一。
之后屏幕上的文字就会随着每次点击而改变。
在这个例子中,从直觉出发,Text方法一定得是被反复调用了,页面才能反复改变他的内容,不然页面没有机会去展示不同的数字。
所以,引起代码重新调用的关键在于MutableState对象。虽然他看起来只是一个普通的ValueHolder,但当他内部的值改变后,会触发个读取这个对象值的代码所在的方法/lambda的重新调用,这部分工作是Compose框架配合Compose编译器帮我们生成的代码来实现的。
最终产生的现象,就是数据改变引起了页面的recompose(重组)。以前我们的思维习惯是拿着数据找View,现在只需要操作数据本身就好,页面的刷新是自动进行的。
当然,处于性能考虑,重组时实际执行到的代码范围会可能会小于上述范围,因为编译过程中会插入各种条件判断语句来帮我们跳过一些代码的执行,具体细节大家感兴趣可以深入研究。
还有一个没见过的东西就是remember { },为了搞清楚他的用途,我们去掉remember的调用,重新运行下看看会发生什么
1 | fun main() = singleWindowApplication { |
为了方便讲解,我稍稍调整了下代码,把按钮部分抽到了Counter方法里。这次并没有使用remember,效果就是,运行起来后无论怎么点击,按钮里的文字都不会发生变化了。
重新捋一捋,按照我们刚刚说的,点击后,给count内的值加一,然后count的值发生了变化,读取count值的代码所在的方法Counter被重新调用,此时可以看到,在方法的第一行,我们又重新创建了一个count对象
将其内部的值重置为0了。于是后面Text方法使用这个值的时候,永远都只能展示初始值。看吧,Compose魔幻归魔幻,方法栈内的临时变量还是跑不出方法的作用域的。
说到底,方法内部是无状态的,不能像类那样创建长生命周期的数据。而remember的意义,就是找个地儿把这些临时变量存起来。只要数据存不乱,没有成员变量一样能行。
至于到底咋存,Compose把这个叫做Positional Memoization。Compose编译器在编译时给每个remember分配一个序号,这样每一行remember都用拥有属于自己的独一无二的key。
将key与数据关联,就可以保证在运行时准确的存取我们想要的信息了。甚至还可以传入自定义的key,一起决定数据有没有被创建或是否有效,从而控制lambda中代码的执行。
在我们的例子中,通过remember,可以保证count对象从始至终只会被创建一次(即lambda只有第一次会被调用),后面每次执行到remember的时候,都是将之前保存的值取出来继续使用。
所以确实存在一个数据结构,来存储运行时产生的各种数据和信息,官方命名为SlotTable。逻辑上以树的形式来存储数据。
除了刚刚提到的remember,调用到的每一个Composable方法都有相应的记录在SlotTable中保存。
这些存储逻辑在编译期自动生成,所以我们会隐约的感受到他们的存在。也就是说,我们调用Composable的过程,其实是更新SlotTable的过程。
除此之外,在Composable方法的执行过程过程中,Compose又帮我们构建了一颗用于渲染的视图树。如果我们追到框架提供的Composable方法的内部,最终会发现框架在帮我们操作视图树中的节点。
有了这棵视图树,关于测量绘制等渲染相关的工作得以展开。当数据变化发生重组时,Compose可以根据SlotTable中收集到的信息的差异,在视图树上帮我们精细高效且智能的刷新UI。
通过这个例子,相信大家已经瞥见了一些Compose背后的运作方式,这些核心组件和流程相互配合,足以支撑我们在此基础上构建一套现代化的声明式UI框架。
值得一提的是,这套基础能力与上层API几乎是不耦合的,意味着第三方开发人员也可以基于这套基础能力,定制出一款属于自己的声明式UI框架。
下面我将跟大家一起,探索一下上层API中那些令人惊艳的设计细节。
Modifier
在安卓中,系统控件有时难以满足业务需求,需要自定义View实现。但随着业务的不断迭代,会发现有些情况下会渐渐力不从心。
假设我们有一个需求,希望给展示的图片填加水印。从展示侧着手的话,使用自定义ImageView可以很好的完成需求。通过覆写onDraw方法,在图片绘制完成后手动绘制水印内容即可。
1 | class WaterMarkImageView : AppCompatImageView { |
还有另外一个独立的需求,希望可以将图片以圆角矩形的形式展示。经过一番考量,我们也决定通过自定义ImageView来实现。在dispatchDraw中使用Xfermode将原始图层抠出透明圆角。
1 | class RoundImageView : AppCompatImageView { |
如果之后我们需要一个既能展示水印又带圆角的ImageView,局面就会变得尴尬起来。
一个最容易想到的办法就是再搞一个新的自定义ImageView,把两份代码拼在一起。
显然,这种做法是不合理且不计后果的。但很遗憾,如果硬要通过自定义ImageView的思路来实现的话,在当前的View体系的设计下,几乎没有特别理想的办法。
问题的核心在于,使用继承来拓展View的能力会受到java下单继承特性的限制,在遇到需要聚合各种独立的拓展功能时,几乎没有办法梳理出合理的继承关系。
在framework实现嵌套滑动功能的过程中,就封装出了NestedScrollingChild/ParentHelper,以便于我们可以通过这种蹩脚的方式来为自己的自定义View提供嵌套滑动的支持。
如果有机会重新设计View的代码,其实稍加放开一些对View的控制能力就可以改善这个问题。比如View可以允许通过非继承的方式来进行一些拓展,拿绘制举例:
1 | class View { |
给外界一个机会可以hook到onDraw中执行,外面的代码以lambda的形式保存在onDrawActions这个list中。
顺着这个思路推演,我们可以在测量、布局、绘制、触摸事件处理等等各个环节都提供这样的能力,甚至把view内置的那些功能,直接剥离出来,变成一个个公开可访问的独立的实现。
使用时可以按需组合自己需要的功能,统一塞到list中由View代为执行。
而这样的设计思路,就是Compose中的Modifier。
在Compose中,Modifier即充当了具体功能实现的载体,也充当了载体的存储容器。不难想象,Modifier可以通过不同的子类来封装不同的功能,
但存储容器的实现方式,其实是一种函数式编程语言中常见的对链表的实现方式。我们用kotlin中的Pair简单复刻一下。
现假设我们有两个数据a和b,希望将其放入一个容器中,如果不用数组或List保存的话,可以直接构造一个Pair硬存一下
1 | Pair(a, b) |
现在有一个新的数据c,也需要跟a b一起放入容器中,如果不用Triple的话,可以再来一个Pair包一层。
1 | Pair(Pair(a, b), c) |
这样就把三个变量存在一个Pair中了。当然,这样的话再来个d e f也不成问题
1 | Pair(Pair(Pair(Pair(Pair(a, b), c), d), e), f) |
套娃就完事儿了,非常好用。所以这就是链表吗?没错这就是链表呀!不信我给你遍历一把
1 | fun foreach(p: Pair<*, *>) { |
如果考虑套娃只套在first字段的话,区分下first
字段的具体类型就可以递归着遍历了。当然这只是一个简单的演示,完善起来的话还要考虑不少细节。感兴趣的同学可以了解下Arrow如何在kotlin上实现通用的函数式链表。
Modifier在实现容器功能时就是通过这样的思路进行封装。Modifier作为链表只能保存Modifier类型的数据,
它是一个接口,定义了添加数据和遍历(fold)数据的方法。
1 | interface Modifier { |
然后定义了一个子类CombinedModifier作为实际的存储数据的容器。与Pair一样,用两个字段来存放两个Modifier类型的数据
1 | class CombinedModifier( |
需要注意的是,outer字段用于存放旧数据,新合并进来的数据放在inner字段,可以把inner这个名字理解为直接存储在当前容器内部的数据。例如:
假设有两个普通的Modifier a和b,将他俩放入一个CombinedModifier中,可以表示为
1 | (a,b) |
此时再添加一个Modifier c,可以表示为
1 | ((a,b),c) |
其中,(a,b)是outer,c是inner,这部分操作直接作为Modifier接口中then方法的默认实现提供。
1 | interface Modifier { |
当然,outer和inner都是Modifier类型的,所以,他们也都有可能是CombinedModifier,发生这种情况时可以理解为给list又addAll了另外一个list
1 | ((a,b),c) + (d,e) -> (((a,b),c),(d,e)) |
其中((a,b),c)是outer,(d,e)是inner。所以在遍历的时候,要考量到outer和inner都是CombinedModifier
的情况,下面是CombinedModifier对fold的实现
1 | class CombinedModifier( |
大家可能在上面的代码中并没有发现他刻意的区分outer和inner到底是不是CombinedModifier。
原因在于对于非容器的Modifier,Compose又单独定义了另外一种类型Element
。也就是说,Compose想达成的效果是,在这个Modifier世界里,除了CombinedModifier,就是Element,这样我们可以依靠多态来完善算法细节。
1 | interface Element : Modifier { |
Element也是Modifier的子类,是一个接口,我们需要通过继承Element的方式来定义真正需要存储的数据。一个Element
就是一个真实独立的数据。这样我们就能通过这两个直接子类,区分开数据和容器了。
基于这样的前提条件,在Element这一层上,可以直接给出对所有Element都通用的fold的实现。
于是在上面的代码中我们可以看到,当Element实现fold方法的时候,其实就是回调他自己。
当我们触发Modifier的遍历时,递归的fold从CombinedModifier出发,一路拆包,最终一定会触及Element的fold方法,从而抵达递归的边界。
拿着Element结合CombinedModifier,配合前面提到的Pair的例子,大家应该可以看懂整个遍历操作是如何进行的了。
现在我们就可以使用Modifier来组织从View中独立出来的各种功能了。假设,我们写好了三种Modifier
1 | class BackgroundModifier(val color: Int) : Modifier.Element { |
他们都是继承自Element,属于链表的元素。使用上文提到的then方法可以使其合成一个链表
1 | val modifiers = BackgroundModifier(color) |
为了让链式调用更加自然,我们针对每个Modifier都使用拓展方法来提供工厂方法
1 | fun Modifier.background(val color: Int) = this.then(BackgroundModifier(color)) |
用Modifier接口的伴生对象作为链式调用的开头部分
1 | companion object : Modifier { |
修改后效果如下
1 | val modifiers = Modifier |
就是我们在Compose中日常使用的形式了。我们可以将modifiers传递给任何需要展示的Composable,框架在渲染视图树的过程中,遍历这些Modifier,执行具体的渲染逻辑。如:
1 | val modifiers = Modifier |
Compose就是通过一系列的Modifier,将各种View内部的功能独立到Modifier中去,
使得我们有能力自由组合想要的功能。
同时又保证了不同View间复用代码的能力,使用起来也不会带来额外的负担,填上了安卓从诞生之初就挖下的大坑。
话说回来,这一套打完,优雅是优雅,但为什么一定要大费周章的重新搞一套链表的实现方式呢?如果只是为了实现这样的API风格,对LinkedList做一定的封装,一样可以达到这个目的。
关于这个问题,我个人的理解,在于这套数据结构提供的不可变性。
考虑我们对普通list添加数据的场景
1 | val list1 = linkedListOf(a, b) |
两行代码执行后,list1和list2内部的数据其实是一样的
1 | list1 : a <-> b <-> c |
如果换做Modifier的话
1 | val list1 = Modifier.then(a).then(b) |
两行代码执行后,list1和list2分别是这样的
1 | list1 : (a,b) |
可以看到,在list1的基础上添加数据,是不会影响到list1本身的。如果想要实现这样的效果,传统的list只能创建一个新的list并将内部的值全部拷贝一遍。
而Modifier在添加数据的时候,虽然会创建新的Modifier,但不需要拷贝内部数据,因为其不可变的特性,可以方便高效的共享数据。
如此一来,外部创建的Modifier可以放心的传递给Compose内部使用,Compose不需要处于安全性考虑在接收数据的时候对数据进行拷贝。
在我们应用层使用Modifier的时候,也可以随意的抽取和复用公共Modifier,提高代码质量。
未来在Compose支持多线程渲染的环境下,Modifier作为一个天生的CopyOnWriteList可以规避并发读写产生的线程同步问题,届时将会发挥出更大的优势。
Kotlin语法特性最佳实践
由于Compose完全基于Kotlin来设计和使用,所以在源码中使用了大量的Kotlin专属的语法特性。Compose对Kotlin的应用,是教科书一般的典范。
Value Class
安卓在设计之初,为了处理不同屏幕密度下的适配问题,提出了dp/sp的概念。这是一种用于表示尺寸的单位,相对于px,可以更好的与现实世界的物理尺寸进行匹配,缓解了复杂机型下的适配压力。
但这也引来了一些麻烦,项目内各处对尺寸的单位需求不一致,很容易导致调用时传入错误单位下的数值。
像是TextView的setTextSize,就提供了重载方法同时指定尺寸和单位来规避这个问题。但这样的方式对双方来说都很麻烦。
还有一种方式是在API设计时标注@Px注解,相当于提醒调用者这里需要传入px单位的数值,但几乎就是一个纯提醒,是完全不可靠的。
这个问题的根源在于,虽然我们在逻辑上区分了px/dp/sp的概念,但形式上都是int类型,人类容易搞混,编译器也帮不上忙。
但如果可以针对不同单位设计不同数据类型,错误就可以在编译期被发现,极大提升开发体验。
但很遗憾,java中的基本类型不可扩充,封装对象类型又会带来成倍的性能开销,这条路目前在安卓上是走不通的。
但幸运的是,kotlin通过编译期的处理,把Project Valhalla的Inline
Class的部分能力带到了更低版本的JVM上,这在kotlin上被称作value class。
value class可以用来包装单一只读数据。比如我们希望创建一个类,来代表一个dp类型的值,其内部只有一个字段,用于表示具体的数值:
1 |
|
在这种场景下,就可以将Dp定义为一个value class。后续使用上与普通class并无区别,但value class可以提供更好的性能。
性能提升的关键在于,当我们声明、创建、访问value class时,Kotlin编译器会将内部的只读数据内联到调用处,从而避免创建对象或是访问成员变量的行为发生。
比如,当我们创建了一个Dp对象并赋值给一个Dp类型的引用时,实际上只是将一个浮点值赋给了一个Float类型的变量。
编译前
1 | val dp: Dp = Dp(16f) //一个用于表示16dp的对象 |
编译后(示意)
1 | val dp: Float = 16f //只是一个普通的值为16f的float |
从类型声明到数据创建,一整个替换的大动作。通过消灭对象的方式,把面向对象的性能开销降到最低。虽然字节码中没有对象存在,但我们在编译期依然可以享受到类型系统带来的好处。(
就像泛型可以参与类型检查但在编译期会擦除)
有了Dp类的存在,Compose中几乎所有关于尺寸的上层api都面向Dp设计,任何尺寸参数的传递,都有类型系统在保驾护航。
想要创建一个Dp对象,通常可以使用Int/Float的属性拓展。如
1 | val a: Dp = 1.dp |
这就与我们在xml里指定尺寸的方式非常相似了。比如在Modifier中使用时:
1 | Modifier |
如果你忘记给数字添加.dp的后缀,IDE会立即发现你传入了错误的数据类型,从而给出一个明显的错误提示。
话说回来,我们知道,dp终归是应用层的概念,渲染时还是得使用真实的px值。关于dp与px的换算。Compose在Density接口中,给出了Dp到px的拓展方法。
1 | interface Density { |
比方说我们想通过Modifier手动绘制一个半径10dp的圆形
1 | Modifier.drawBehind { |
radius参数传入的就是10dp对应的px值。这里可以直接访问到toPx这个拓展方法,是因为lambda的接受者是Density
的子类,对于非Density上下文的情况,可以使用Kotlin自带的作用域函数来提供调用环境
1 | val density = LocalDensity.current |
至此,关于dp的问题便得到妥善的解决了。从这个思路出发,其他类似的、需要进行封装的数据,像是sp、color等等都能得到妥善的处理。
看到这里,有人可能觉得通过value class实现Dp类的设计不过是锦上添花,只是针对编程体验上的改进。
但下面我要讲的关于矢量封装的例子,可以说是雪中送炭了。
上文在介绍value class时提到,value class只能封装单一值,对于矢量这种包含多维信息的数据目前是无法实现的。比如假设我们有一个DpOffset类,其内部保存了x和y两个方向上偏移量的dp值。
1 | class DpOffset(val x: Dp, val y: Dp) |
这种对象本质上就是二维矢量,用来表示View的位置信息或是二维空间中的坐标信息都是非常合适的。但很遗憾,我们无法直接将其改写为value
class,出于性能上的考量这样的封装就不具备实用价值了。
但如果可以拿一点点计算去换空间呢?Dp本质上不过是一个32位的Float,如果我们用一个64位的Long来存储两个Float,使用的时候再将数据还原回来,对于value
class来说,已经完全符合使用要求了。
1 | fun DpOffset(x: Dp, y: Dp): DpOffset = DpOffset(packFloats(x.value, y.value)) |
packFloats就是将两个Float合并为一个Long的操作。DpOffset的类定义可以改写为:
1 |
|
这里使用internal constructor就是避免我们直接给packedValue赋值,从而引起预期外的行为。可以使用上面与类名同名的工厂方法代替构造方法的调用。当我们需要获取x方向或y方向上的偏移量时,可以将数据从packedValue中解析出来:
1 |
|
这样DpOffset就完全可以通过value class实现了。于是对于二维矢量的创建、获取、计算等等场景,都可以面向对象得实现。虽然DpOffset中的值是只读的,但我们完全可以大胆的用创建新对象的形式来代替修改内部数据的行为。且这种作法杜绝了计算过程中数据被意外篡改的可能,在性能和开发效率上取得了完美的平衡。
可能有朝一日,
当Compose在安卓上成为主流的UI框架的时候,
那些从Compose入行的年轻开发者很难想象,
当年我们通过传入int数组的方式来接收View在屏幕中的坐标值,
是怎样一段艰苦的时光。
特定作用域下的拓展函数
考虑一个关于layout_gravity的问题。
在xml中我们可以给子控件设置layout_gravity属性来规定子控件相对父布局的对齐方式。但由于不同布局对控件排布方式不同,layout_gravity并不总是生效的。
不得不承认,这确实有些瑕疵,但是可以理解。
在Compose中,指定对齐方式一般也是通过Modifier来进行的,需要调用Modifier.align(),传入具体的对齐规则即可。Compose把这个规则拆的很细,用了三个interface分开描述。
1 | fun interface Alignment { |
大家可以看到,这几个interface里面都各自定义了一个align方法。由于不同的对齐方向所涉及到的具体的计算逻辑要严格区分,所以不存在继承关系。
Alignment代表的是二维上的对齐,他要描述的是x、y两个方向上的对齐方式,比如TopStart、BottomEnd等等共九个。Alignment.Horizontal代表的是水平方向上的对齐,是一维上的对齐,就只有Top、CenterVertically、Bottom三个。Alignment.Vertical是Start、CenterHorizontally、End三个。
虽然很多,但是这些规则都已经被实现好了,可以直接调用。Compose为我们提供了这15个对齐规则的实例:
1 | fun interface Alignment { |
然后我们看下在Box(FrameLayout)中如何使用
1 | Box { |
我们再看下在Row(横向LinearLayout)中的使用方式
1 | Row { |
这与我们在xml里的写法非常相似。但是大家回想一下,在xml中给横向LinearLayout的子View指定layout_gravity时,
无论写center_vertical还是center_horizontal还是center都不会有错误提示,可实际上center_horizontal和center这两个值都是不正确的。
如果我们在Compose下也试图给Row中的Text传入Alignment.Center或Alignment.CenterHorizontally,IDE会直接给出错误提示,告诉我们align()方法只能接收Alignment.Vertical类型的参数。
由于Alignment.Center是Alignment类型(二维对齐),Alignment.CenterHorizontally是Alignment.Horizontal类型(水平对齐),都不是我们需要的Alignment.Vertical类型(纵向对齐),所以这里直接报错了。
得益于精细的类型区分,编译器可以直接帮我们发现这个错误。
但如果再回看一下在Box中调用的align()方法,此时你会惊奇的发现,这个align()声明的参数类型,竟然跟Row中是不同的。
- Row -> Modifier.align(alignment: Alignment.Vertical)
- Box -> Modifier.align(alignment: Alignment)
那只能说明一个问题,Box中调用的align()跟Row中调用的align()并不是同一个方法。

原因就在于,RowScope和BoxScope分别针对Modifier定义了不同的align()方法。
1 | interface RowScope { |
1 | interface BoxScope { |
这使得在不同的父布局下,Modifier可以调用到不同的功能。这不仅仅可以帮助我们检查代码的错误,也让Modifier这个设计变得更加通用、灵活。如果没有特定作用域下对Modifier的拓展,所有的功能都以公开的方式存在,问题可要比在xml中乱写gravity严重的多了。
更友好的API设计
还有一些kotlin的语法特性,帮助Compose封装出了更为友好的API
属性代理
在编写Compose Demo的时候,我们提到,使用MutableState来维护页面中的数据。
1 | val state = remember { mutableStateOf(0) } |
使用时需要访问其内部的value变量
1 | //写 |
Compose为我们提供了MutableState的属性代理,使用后代码可以简化为
1 | var state by remember { mutableStateOf(0) } |
用起来就跟一个普通变量没有区别了。
方法的默认参数
在安卓中,如果要在代码中设置view的padding,可以调用
1 | view.setPadding(l,t,r,b) |
但如果我只想更新topPadding,就会有点麻烦
1 | view.setPadding( |
即使我可以确保除了topPadding,其他方向的padding都是0,也必须要写作:
1 | view.setPadding(0,topPadding,0,0) |
Compose也觉得这事儿忍不了,借助方法的默认参数,Modifier.padding()的API被设计为
1 | fun Modifier.padding( |
仅设置paddingTop可以写作
1 | Modifier.padding(top = topPadding) |
值得一说的是,在androidx给View提供的拓展方法中,也有类似的写法
1 | inline fun View.updatePadding( |
参数的默认值取得是view中当前的padding值。这根Compose的处理是不同的。
个人认为,view作为一个对象,可以被传递、被修改。创建view和修改viewpadding的代码大概率不在同一处,使用update更为方便安全。而在Compose中,声明式的编程方式导致我们无法像View那样从视图对象中获得内部状态,所有的状态都是我们在外部主动管理的。所以Modifier给出的默认参数是0dp也可以理解。而这也是我们需要转换思维方式的地方:涉及到变化的视图属性,一定要有state支撑,当我们需要更新视图属性时,update的主体应该是数据,而非Modifier。
使用协程处理触摸事件
触摸事件处理可以认为是一种典型的异步任务处理工作。用户触摸事件从触摸驱动通过binder线程分发至应用层,我们与framework层配合,对异步事件进行分发、转换、识别、处理,最终体现在UI的变化上。不同于一般的业务数据的网络请求处理,触摸事件处理需要考虑到当前事件与历史事件之间的关联,涉及到更为复杂的状态管理与逻辑判断。在安卓源码中对长按、双击、滑动等操作动辄上百行的识别逻辑中我们就可以意识到,针对触摸事件,传统的基于回调的异步代码,是非常难以编写和维护的。
而这正是协程的优势。与其说协程可以把异步回调转换为同步阻塞,倒不如说协程可以给异步任务带来共享同一条/多条线程计算资源的能力。只要异步任务不是需要一直占据cpu计算资源的,在协程挂起后都可以将当前协程所在的线程的执行权利让渡给其他协程使用。在线程使用受限的情况下(如处理触摸事件发生在主线程),让我们有机会将响应式的代码风格,转变为同步阻塞的形式,掌握异步事件处理的主动权。
在Compose中,处理自定义触摸事件也是通过Modifier来进行的。
1 | Modifier.pointerInput { |
pointerInput方法传入的是一个suspend lambda,其定义为
1 | suspend PointerInputScope.() -> Unit |
receiver PointerInputScope为我们提供了viewConfiguration、当前视图区域的大小等数据,同时提供了方法 awaitPointerEventScope,用于帮助Compose拿到当前协程的Continuation,以便于在触摸事件到来时,恢复被我们挂起的协程。所以,当我们使用协程处理触摸事件时,可以通过awaitPointerEventScope获得协程运行环境:
1 | Modifier.pointerInput { |
AwaitPointerEventScope中,为我们提供的最为基础的api叫做awaitPointerEvent,他的作用就是阻塞当前协程,直到有一个触摸事件到来。方法定义如下
1 | suspend fun awaitPointerEvent(pass: PointerEventPass = PointerEventPass.Main): PointerEvent |
返回值PointerEvent中包含了这个触摸事件的类型(down/up/move等)、坐标值、pointerId等等信息。于是,我们可以反复调用此方法,来持续不断的获取触摸事件。
1 | Modifier.pointerInput(Unit) { |
起一个死循环就能保证不遗漏的监听到所有的触摸事件,协程嘛,阻塞着挥霍就完事儿了。
把这个Modifier设置给某个Composable组件,运行上述代码,触摸这个Composable后,可以看到控制台中出现了从 down 到 move 到 up 的一系列输出。
这就跟我们所熟知的onTouchEvent非常类似了。我们知道,触摸事件一般会成组出现,从一个actionDown开始,经历一系列的move,最终以up/cancel结束。现假设我们有一个需求,需要在down发生之后,up之前,第一个move到来时打一个log,且每个周期内只能打印一次,按照我们目前所了解的知识,给出的一个思路如下:
- 根据event的类型(down/up),识别出一个周期的开始和结束。
- 当move到来时,判断当前周期内有没有打过log,在第一次move时打印
这个思路好像没问题,但看下来感觉用协程跟不用协程好像没啥区别,为了实现这个思路,免不了还是要定义一些flag,来维护在事件流中所处的状态。根本原因还是在于我们在单次while循环中处理的粒度太细了,导致协程的能力没有发挥出来。
调整下固化的思维,回头再看一眼awaitPointerEvent方法,他的作用是阻塞当前协程,直至有触摸事件到来。由此得到启发,是不是可以封装一个方法,阻塞当前协程,直至down事件的到来:
1 | suspend fun awaitDown() { |
类似的,我们也可以封装await单次move的方法、await最终的up/cancel的方法等等,更进一步的拓宽单次阻塞的粒度。当然我上面给出的实现只是一个简单的例子,Compose为我们提供了丰富的开箱即用的await系列api:
阻塞直到第一根手指按下
awaitFirstDown()阻塞直到产生一次move或cancel到来
awaitDragOrCancellation()阻塞直到滑动超过一个TouchSlop或cancel到来
awaitTouchSlopOrCancellation()阻塞直到up或cancel到来
waitForUpOrCancellation()
有了这些挂起方法,我们可以重新考虑上述需求的实现:
1 | awaitPointerEventScope { |
如此改造下来,一个循环体就可以处理一条完整的事件流,通过各个挂起方法相互配合,可以非常自然的完成我们的需求。
其实对于以单次事件流为单位来处理触摸事件的需求非常常见,Compose帮我们封装了forEachGesture方法,使我们可以专注于处理单次事件流内部的逻辑。
1 | suspend fun PointerInputScope.forEachGesture(block: suspend PointerInputScope.() -> Unit) |
他的实现方式是以actionUp为分割点,反复重新调用block内的代码。如此一来,相当于forEachGesture可以为我们提供阻塞当前协程直至单次事件流结束的能力,当一轮事件处理完成后,代码可以从block的第一行重新执行。这样的话我们的代码可以进一步改造
1 | forEachGesture { |
代码非常言简意赅,就是判断一下用户是不是按下了,又滑动了,且滑动的距离不为0,如果是的话,就是第一次Move了,此时就可以打log。之后当前协程阻塞,在下一组事件流到来之时,代码又会从头执行。讲到这里,大家是不是已经找到些感觉了?使用阻塞的方式来编写事件处理的代码,确实是非常奇妙的体验。下面我将利用我们了解到的这些知识,实现一个长按后拖动的功能,给本篇的知识点做一个实践。
需要实现的效果是,利用本篇开头demo中的代码,给HelloWorld添加一个长按拖动的功能,文本在长按后自动放大,之后可以拖拽HelloWorld至任意位置。
首先我们不考虑触摸事件的处理,单纯的完善下UI细节。
1 | fun main() = singleWindowApplication { |
注意到,新增了两个MutableState,offset用于表示位置的偏移量,等下我们拖动文本的时候,就可以通过改变offset的方式来触发页面刷新。scale用于表示文本的缩放,当长按发生时,改变scale的值即可产生长按后放大的效果。
然后看下处理触摸事件的代码
1 | Modifier.pointerInput(Unit) { |
大家可以看到,长按->放大->拖动更新位置->复原缩放,一整套流程被我们在协程中简单且自然的表达出来。唯一需要解释下的点是,当我们识别长按时,是利用了协程的超时功能。在actionDown发生后,我们立刻使用withTimeout来感知内部代码的超时行为,通过awaitPointerEvent阻塞当前协程,如果在viewConfiguration.longPressTimeoutMillis时间内没有新的事件到来,则认为用户成功的完成了长按操作。

当然,上面的代码只是用于演示,还有多点触摸和touchSlop等相关的处理细节需要完善。但幸运的是Compose针对PointerInputScope提供了一系列detectXXX的拓展方法,用于帮助我们识别点击、长按、滑动、双击、长按拖动等等手势,相当于将安卓的GestureDetector整合进Modifier中来。如果提供的能力不能满足业务需求的话,依然可以选择使用更加底层的awaitXXX系列API来实现出我们想要的功能。
写在最后
坦率的讲,这是我人生中第一次接触声明式的UI框架,随着我对他的了解不断深入,会时长感叹原来代码还能这么写。
Compose把声明式的代码风格、增量式的UI刷新、Kotlin的语法特性及协程融入到一款跨时代意义的UI框架中,为我们带来了全新的编程体验。
限于篇幅,还有很多优秀的细节没能跟大家分享,希望大家多多尝试,亲自体验下Compose的魅力。
我们下一篇再见。